Stability AI has recently introduced their latest cutting-edge model, Stable Code 3B, tailored for code completion across multiple programming languages, boasting additional capabilities. This model serves as a successor to Stable Code Alpha 3B, having been trained on an extensive dataset of 1.3 trillion tokens, encompassing both natural language and code data in 18 programming languages. Remarkably, Stable-Code-3B achieves a 60% reduction in size compared to existing models like CodeLLaMA 7b while maintaining top-tier performance.
Utilizing an auto-regressive language model based on the transformer decoder architecture, Stable-Code-3B introduces innovative features such as the Fill in Middle Capability (FIM). The model is trained on 16384 long sequence tokens, allowing it to handle extended contexts effectively. Noteworthy components include rotary position embeddings and a specialized tokenizer designed for in-middle capability, along with other tokens. Training was conducted on diverse open-source large-scale datasets, leveraging a robust infrastructure with 256 NVIDIA A100 40GB GPUs. The optimization was carried out using AdamW in bfloat16 precision, and the model operates under 2D parallelism with ZeRO-1. Incorporating elements like flash-attention and Rotary Embedding kernels from FlashAttention-2 further enhances its capabilities.
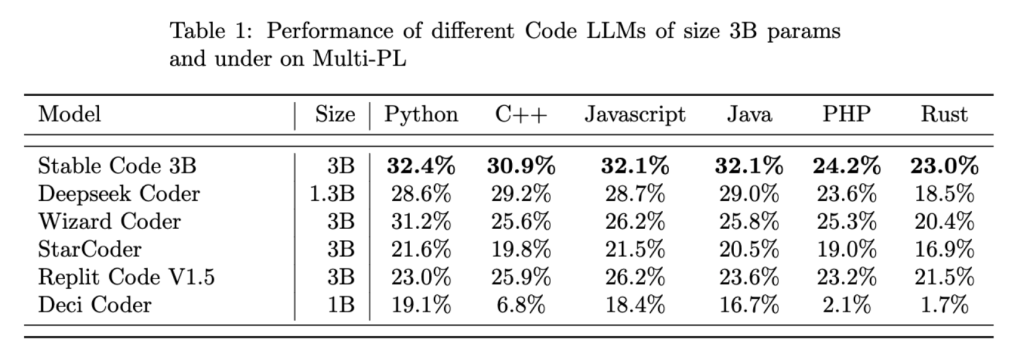
Experimental results, involving six existing models across various programming languages (CPP, Rust, Python, Java, PHP, and JavaScript), demonstrate Stable-Code-3B’s efficiency, achieving an impressive 30% accuracy. While some models outperformed in specific languages or boasted larger sizes, Stable-Code-3B proves itself as a formidable tool for developers seeking a foundational base in natural language processing applications.
However, it’s crucial to acknowledge the model’s limitations and potential biases. Being a foundational model, it necessitates careful evaluation and fine-tuning for reliable performance in specific downstream applications. Developers must remain vigilant regarding possible undesirable behaviors, conducting thorough assessments and corrections to ensure the model aligns with ethical and safety standards before deployment.